I perioden op til kommunal- og regionsvalget i forrige måned kunne man ikke undgå at høre, at valgdeltagelsen var faldende. Ikke mindst, at valgdeltagelsen blandt unge var alarmerende lav, fordi unge var uengagerede og ligeglade over for lokalpolitik. Der blev derfor lanceret massive kampanger i forskellige medier for at få flere til at gå til stemmeurnerne. At få flere til at stemme til lokale valg er selvfølgelig en god ide, men det lokale demokrati er ikke i fare i Danmark. I hvert fald ikke på den måde det blev fremstillet i medierne.
Der er selvfølgelig lidt om historien. Hvad der blev refereret i medierne relaterer tilbage til en undersøgelse fra Københavns Universitet, hvor forskere i valgdeltagelse havde undersøgt deltagelsen til kommunalvalg i 1997, 2001 og 2009, baseret på data fra valgstederne. I rapporten over undersøgelsen, baseret på registerdata, blev der set på mange forskellige faktorer i forhold til valgdeltagelse, f.eks. køn, uddannelsesniveau, alder og etnicitet. Denne undersøgelse viste ganske rigtigt et fald i valgdeltagelsen fra 1997 til 2009.[1]
Problemet er imidlertid, at, i modsætning til hvad der blev antydet i medierne i forbindelse med offentliggørelsen af denne undersøgelse, så er en sammenligning mellem to punkter, såsom valgdeltagelsen i hhv. 1997 og 2009, ikke er tilstrækkeligt til at sige, om der er en faldende (eller stigende) tendens. Selvom vi kan se, at der er så-og-så mange flere eller færre, der har stemt fra år til år. Selvom det er nemt at komme til at tro, at der er tale om en trend på denne måde, kan man imidlertid ikke drage denne slutning. Grunden hertil skal findes i de grundlæggende principper for dataindsamling og statistik.
Cherry picking og tilfældig variation
Når man laver undersøgelser er observationer, dvs. de tal og værdier man måler/indsamler etc., altid behæftet med en vis usikkerhed. Dette gælder alt lige fra mikroskopiske observationer af elektroners spin til observationer af galaksers placering, og altså også demografiske undersøgelser, eksempelvis af valgdeltagelse. Hvis vi nøjes med at se på to uafhængige observationer, kan vi ikke sige, hvorvidt en eventuel forskel mellem de to skyldes tilfældig variation, eller om den er forårsaget af en forklarende faktor. I forhold til valgdeltagelse kan en mulig forklarende faktor eksempelvis være, at unge ikke gider lokalpolitik, hvilket man måske nemt kan få indtryk af er tilfældet.
At udvælge bestemte datapunkter ud fra et potentielt større dataset – f.eks. at sammenligne valgdeltagelse i to arbitrære årstal, når der forligger data om valgdeltagelse for mange flere år – er, hvad man inden for statistik kalder ”cherry picking.” Man vælger så at sige de gode kirsebær, der støtter ens pointe, men ser bort fra de rådne kirsebær, som ikke passer til den konklusion man gerne vil frem til. Dette er, medmindre man har et stærk teoretisk argument herfor, at snyde med statistikken. Som udgangspunkt bør man inkludere alle tilgængelige observationer i en undersøgelse, når man søger at lave slutninger på baggrund heraf.
Et velkendt eksempel kommer fra klimastudier og forskning i global opvarmning. Her kan man vise, at den globale temperatur jævnligt har været faldende over de sidste fyrre år, også selvom den globale temperatur er stigende, hvilket selvfølgelig er selvmodsigende, hvis det drejer sig om det kontinuerte forløb gennem hele perioden.[2]

Eksempel på at hvis man kun kigger på dele af et dataset, kan man let komme til forkerte konklusioner, her at den globale temperatur er faldende. Dette gælder kun når man kigger på korte tidsintervaller, hvorimod tendensen er klart stigende over hele perioden. Figur fra http://www.skepticalscience.com
Ovenstående figur er netop et godt eksempel på, hvordan tilfældig variation omkring en ellers tydelig trend let kan blive misforstået, hvis man kun vælger et lille udpluk af datapunkter. At variation er tilfældig betyder ikke, at der ikke kan findes specifikke årsager til tendenser man observerer, såsom stigende eller faldende valgdeltagelse.
Når “tilfældig variation” bruges i denne sammenhæng, så referer det til det faktum, at der potentielt er mange flere faktorer, end vi kan holde styr på. Faktorer, der godt nok påvirker vores observationer, men ikke på samme systematiske måde som den faktor, vi er interesseret i at sige noget om. Et eksempel er vejr-cyklusser, som gør at nogle år er varme og nogle år kolde, selvom udviklingen over en længere periode er, at det generelt bliver varmere. I samfundsmæssige undersøgelser er der altid utallige potentielle variabler, som man ikke kan udelukke påvirker det datasæt, man kigger på. Antagelsen er dog, at disse forstyrrende faktorer ikke har en systematisk påvirkning. Så hvis vi har tilstrækkeligt med observationer, vil gennemsnittet af de forstyrrende faktorer være nul (hvad der med en teknisk betegnelse kaldes hvid støj).
Dette problem kan vi komme over ved at inkludere flere datapunkter og teste hvorvidt, vores observationer er forskellige fra tilfældig variation. Dette betyder, at sammenligninger af deskriptiv statistik, hvor man udelukkende angiver optællinger, procent osv., hvor sammenligningen ikke indeholder nogen test af, hvorvidt en eventuel observeret forskel er forskellig fra tilfældig variation, ikke kan bruges til at konkludere noget om tendenser og sammenhænge.
Udviklingen i valgdeltagelsen ved kommunalvalg
Specifikt i forhold til valgdeltagelse ved kommunalvalg bragte Kommunernes Landsforening (KL) en artikel, hvor de sammenligner fald i valgdeltagelsen ved kommunalvalg i Danmark, med valgdeltagelsen ved kommunalvalg i Sverige. Ud fra tilgængeligt statistisk materiale konkluderende de, at svenskerne har fået vendt en ellers faldende valgdeltagelse ved kommunalvalg.[3]
Kigger man på figuren herunder kan man da også se, at de seneste tre valg i Sverige har haft højere valgdeltagelse end det foregående, hvor valgdeltagelsen i Danmark er faldende i samme periode:
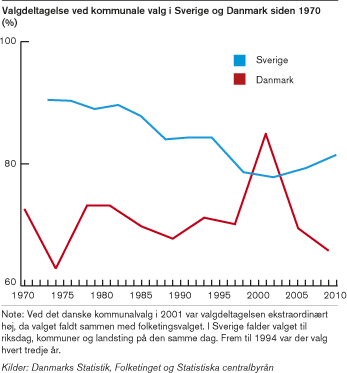
Valgdeltagelsen ved kommunalvalg i Danmark (rød) og Sverige (blå) over de sidste 40 år. Figur fra kl.dk
Men denne konklusion er netop, som nævnt ovenfor, baseret på kun en lille del af en større mængde data (de gode kirsebær), ved ikke at forholde sig til de forudgående datapunkter. Der er ingen test for, hvorvidt det seneste fald i Danmark og opsvinget i Sverige kan tilskrives tilfældig variation, som beskrevet ovenfor. Ser man over hele perioden, ser det faktisk ud som om, at valgdeltagelsen i Sverige er jævnt faldende, hvorimod den svinger mere i Danmark. Hvis vi tager tallene for valgdeltagelsen i Danmark og Sverige fra KL og prøver at se på udviklingen i valgdeltagelse i de pågældende årstal som en lineær udvikling, ser vi, at tendensen er det modsatte af KLs konklusion.[4]
Deltagelsen ved kommunalvalg i Danmark er tæt på at være konstant. Hældningen på linjen er 0,2. Konfidensintervallet for hældningen er dog [-1,0; 1,5]. Da dette interval indeholder nul, betyder det, at hældningen ikke er signifikant. Vi kan derfor ikke konkludere, at der er nogen negativ (eller positiv) tendens i valgdeltagelsen ved kommunalvalg i Danmark over de sidste fyrre år.

Udviklingen i valgdeltagelse ved kommunalvalg i Danmark (rød) og Sverige (blå) over de sidste 40 år, svarende til figuren ovenfor. Her med en lineær tendenslinje plottet hen over.
Tendensen i Sverige er derimod jævnt faldende med hældningen -1,2 og konfidensinterval [-1,6; -0,8]. Dette resultat er signifikant, så vi kan konkludere, at trenden for valgdeltagelsen ved kommunalvalget er faldende i Sverige med et fald på mellem 0,8 og 1,6 procentpoint per kommunalvalg. De årstal vi brugte gik fra 1970-2009, så det vil være nærliggende at se, hvorvidt valgdeltagelsen ved kommunalvalget fortsat er konstant, som trenden antyder, eller om valgdeltagelsen er stigende, som f.eks. DR skriver og giver de mange kampagner kredit for.[5]
Vi vil derfor se, om vi kan forudsige valgdeltagelsen ved kommunalvalget i år ud fra den lineære tendens, ved at lægge ét valg til ovenstående. Dette giver, at vi, ifølge den lineære tendens fra 1970-2009, måtte forvente at valgdeltagelsen i år vil være på 72,3 procent [64;81]. Dette er ikke langt fra hvad valgdeltagelsen rent faktisk var i år, nemlig 71,9 procent.

Valgdeltagelsen ved kommunalvalg i Danmark og lineær tendens, med 95% Konfidensinterval (stiplede linjer). Det grønne punkt angiver valgdeltagelsen ved kommunalvalget i år.
Den lineære tendens for valgdeltagelsen i Danmark er dog ikke så præcis, siden der er en del variation mellem de enkelte valg (se de stiplede linjer i figuren ovenfor). Dette har betydning for, hvor præcise forudsigelser vi kan lave ud fra den statistiske model. Konfidensintervallet for forudsigelsen af valgdeltagelsen i år går fra 64 procent til 81 procent, hvilket er en stor usikkerhed. En del af variationen stammer fra kommunalvalget i 2001, som faldt samtidig med folketingsvalget samme år. Folketingsvalg har generelt en højere deltagelsesprocent end kommunalvalg. Det kan derfor overvejes, hvorvidt valgdeltagelsen i 2001 kan betragtes på lige fod med de andre (og om denne afviger evt. er grunden til, at vi ikke ser nogen signifikant udvikling, som det ellers påstås). Vi prøver derfor at gentage proceduren ovenfor, men ekskluderer nu dette punkt for valgdeltagelse i 2001.[6]
Dette giver en bedre præcision. Forudsigelsen for valgdeltagelsen i år giver nu 68,2 procent, med konfidensintervallet [62,7; 73,7]. Den reelle valgdeltagelse på 71,9 procent, er altså stadig inden for konfidensintervallet og stadigvæk inden for hvad ville forvente ud fra tilfældig variation. Hældningen på linjen, dvs. den lineære udvikling, er nu -0,2 med konfidensinterval [-1,0; 0,6]. Konfidensintervallet indeholder altså stadig nul, og vi kan derfor hverken sige, om der er en negativ eller positiv tendens i valgdeltagelsen ved kommunalvalg.

Valgdeltagelsen ved kommunalvalg i Danmark (undtagen 2001) og den lineære tendens, med 95% Konfidensinterval (stiplede linjer). Det grønne punkt angiver valgdeltagelsen ved kommunalvalget i år.
Når vi tilpasser en lineær tendens til valgdeltagelsen ved kommunalvalg over en årrække, som ovenfor, siger det dog ikke direkte noget om, hvilke faktorer, der ligger til grund for hvorfor valgdeltagelsen er enten højere eller lavere et givent år. Alt hvad vi kan sige noget om er, at der ikke er noget i ovennævnte data, der kan påvise, at valgdeltagelsen er faldende. Vi kan heller ikke konkludere, at valgdeltagelsen endelig er begyndt at stige igen i 2013, idet valgdeltagelsen for i år falder inden for det, vi ville forvente baseret på den lineære tendens over de forudgående ca. 40 år. Hvad vi kan sige om valgdeltagelsen ved kommunalvalget i Damark siden 1970 er, at tendensen ikke er forskellig fra tilfældig variation. Den formodede krise, som det danske demokrati er i pga. manglende vælgeropbakning, er altså ikke større end det, der er forventeligt i forhold til tilfældig variation.
[1] Bhatti, Y. & Hansen, K. M. (2010) Valgdeltagelsen ved kommunalvalget 17. november 2009. Beskrivende analyser af valgdeltagelsen baseret på registerdata . Arbejdspapir 2010/03, Institut for Statskundskab, Københavns Universitet. Der blev foretaget mange forskellige sammenligninger i ovenstående rapport baseret på store mænger data. Det er ikke metoden eller konklusionerne i rapporten vi anfægter i dette indlæg, da vi ikke på nogen måde har gennemgået samme mænge data. Derimod forsøger vi at afvise nogle af de misforståelser, som nyhedsmedier synes at have fået ud af rapporten. Forfatterne bemærker i starten af rapporten, at valgdeltagelsen ved kommunalvalg i Danmark har været stabil – præcis som vi også viser i dette indlæg.↩
[2] For gennemgang af statistikken i forhold til global opvarmning se mere på http://www.skepticalscience.com/going-down-the-up-escalator-part-1.html og http://www.skepticalscience.com/going-down-the-up-escalator-part-2.html.↩
[3] http://www.kl.dk/Momentum/momentum2013-14-4-id137957/.↩
[4] Vi har prøvet at rekonstruere de egentlige værdier for valgdeltagelse, da jeg ikke kunne finde dem på Danmarks Statistiks hjemmeside. Jeg har i stedet brugt de tal som er oplyst i http://politiken.dk/indland/politik/Kommunalvalg/ECE2137600/stemmeprocent-var-den-hoejeste-i-mange-aar/ og http://www.kl.dk/Momentum/momentum2013-14-4-id137957/ og derudover ”gættet” mig til værdierne, ved at aflæse figuren fra http://www.kl.dk/Momentum/momentum2013-14-4-id137957/. Den lineære regression er en simpel regression med valgdeltagelsen i procent som observation og nummer valg siden 1970 prediktor. Det giver mere mening at bruge rækkefølgen af valg som prediktor i denne model, frem for årstal, for det første fordi kommunalvalgene ikke har været afholdt periodisk med fire års mellemrum, og for det andet fordi det giver mere mening at sige noget om den lineære udvikling fra valg til valg frem for fra år til år, da der ikke er valg hvert eneste år. ↩
[5] http://www.dr.dk/Nyheder/Politik/KV13/Artikler/Hele_landet/2013/11/20/035549.htm. ↩
[6] At ekskludere enkelte punkter som afvigere er noget man generelt skal være forsigtig med. Som udgangspunk skal man ikke gøre det, med mindre man uanfægtet kan vurdere, at dette punkt ligger uden for hvad man kan forvente; at man har en teoretisk grund hertil; eller at man ved, at dette datapunkt er blevet påvirket af utilsigtede omstændigheder, som gør det meningsløst at sammenligne med andre observationer. At ekskludere år 2001 kan derfor retfærdiggøres, da valget faldt sammen med folketingsvalg, hvor valgdeltagelsen normalt også er højere. ↩



